ITサービスが身近になった昨今、個人・企業の活動はシステムありきの前提で成り立っています。人々の暮らしを豊かにする便利なITサービスですが、サービス運営者にとって恐ろしいのがシステムトラブルです。
ひとたびシステムが停止すると、顧客に多大なる影響が発生し迷惑をかけるばかりか、障害の原因や影響次第では、損害賠償を請求される恐れもあります。
この記事では、東京証券取引所で発生した大規模なシステム障害の事例や、トラブル発生時の責任の所在などについて解説します。
Contents
東証のシステム障害とは?
2020年10月19日、東京証券取引所で大規模なシステム障害が発生し、その影響により終日株式売買が停止したことが大きくニュースでも取り上げられました。
障害が発生したのは、富士通が開発し東京証券取引所が運営していた「arrowhead」という株式売買のシステムです。
株式売買のシステムは、止まることが許されない重要なシステムであるため、当然ながら arrowheadも多少の障害でシステムがダウンしない設計とされていました。しかし、それでも障害が発生しました。
明らかになった障害の原因
障害発生から程なくして、障害の原因が共有ディスク(NAS)装置のメモリ故障であることが明らかになりました。共有ディスク装置とは、LANなどを経由して複数のサーバーから読み書きできるストレージで、arrowheadのような大量の取引データを扱うようなシステムでは、高性能で障害に強い共有ディスク装置が用いられます。
一般的なパソコンは、1つのHDDまたはSSDにすべてのデータを格納し、そのHDDやSSDが故障するとデータの読み出しが出来なくなり、最悪の場合はパソコンデータをすべて初期化する必要があります。
家庭用のパソコンならまだしも、株取引などの重要なデータを扱うarrowheadで、たった1つのHDDの故障でシステムが停止したり、データを損失したりすることは許されません。
そこで共有ディスク装置には、次のイメージのように複数のHDD/SSDが搭載されており、それを制御するための「ストレージコントローラ」がセットになっています。
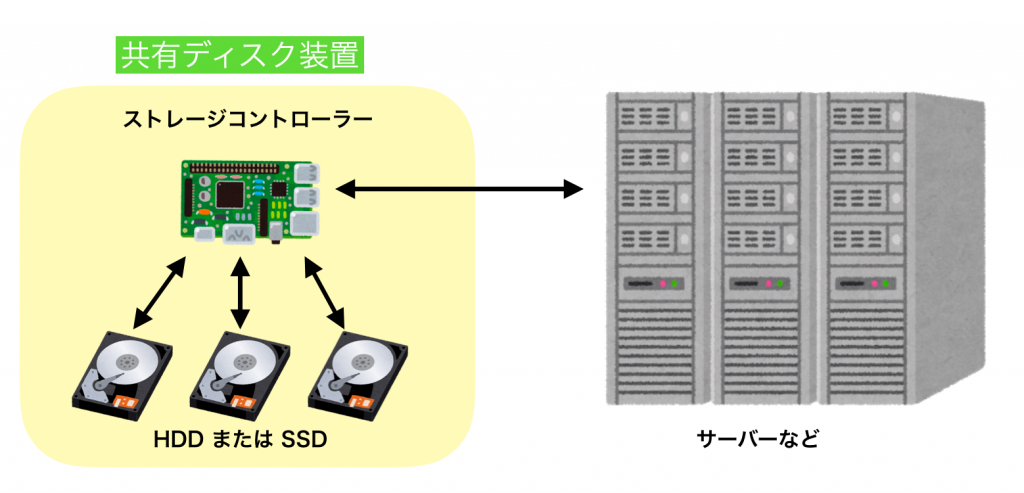
重要なデータを扱う場合、ストレージコントローラは通常、同じデータのコピーを複数のHDDまたはSSDに書き込みます。複数に書き込むことにより、1つのHDDで故障が発生しても、共有ディスク内の別のHDDにコピーが存在するため、データを損失することなく、システムを稼働させることが可能になります。
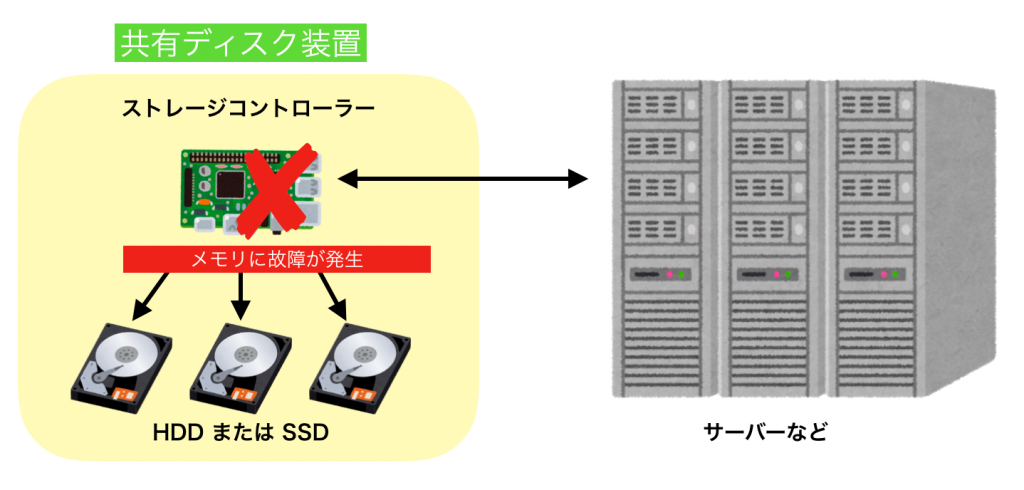
ただし今回の障害は、共有ディスク装置のメモリに障害が発生したため、装置内のすべてのHDD(もしくはSSD)にアクセスできなくなり、上述の機能は働きませんでした。
arrowheadは、共有ディスク装置自体が使用できなくなった場合に備え、1号機の障害発生時には2号機の共有ディスク装置に自動的に切り替わるフェールオーバー機能が備えられていました。今回の障害は、このフェールオーバー機能によって2号機に自動的に切り替わり、システムが正常に稼働する設計でした。
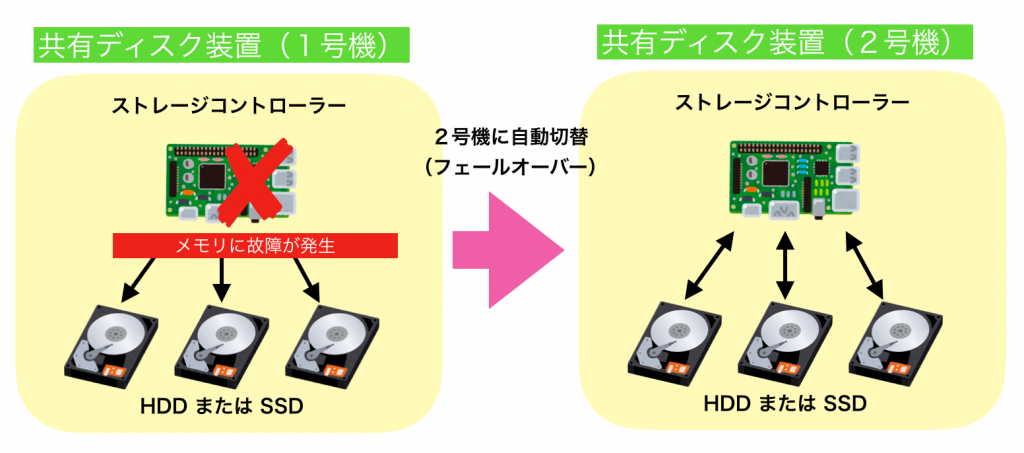
しかし、結果はニュースで報道のとおり、終日の取引停止となるシステム障害が発生してしまいました。
なぜ、対策していたはずのシステムに障害が発生したのでしょうか?
東証の発表によると、開発ベンダーの富士通が提示したマニュアルと、共有ディスク装置の実際の動作(仕様)に食い違いがあり、フェールオーバー機能が働かなかったと説明がありました。
具体的には、初代の共有ディスク装置を導入した際は、自動切替をOFFに設定したままでも、トラブル発生時に15秒後に切替(フェールオーバー)が行われるため、富士通側のマニュアルには自動切替の初期設定をOFFに設定するようにマニュアルを記載しました。
しかし、2代目以降の共有ディスク装置は、自動切替がOFFではバックアップが作動しないように仕様変更があったのです。そのことに富士通側が気付かず、2代目以降も自動切替をOFFに設定して東証に導入していたため、今回の障害が発生しました。
つまり、今回の障害の根本原因は、共有ディスク装置を2代目、3代目に交換した際の動作検証不足・マニュアル不備という、人為的なミスが招いた障害であることが分かったのです。
ここまでが、2020年10月19日に東証で発生した大規模障害の事の顛末です。


「ふくいナビ」の障害、クラウドの全データ消失
2020年11月には、ふくい産業支援センターが運営する「ふくいナビ」のウェブサイトにアクセスできない障害が発生しました。
同センターは、ウェブサイトで使用しているクラウド環境の契約が、10月31日に切れるため、事前にサーバー管理会社であるNECキャピタルソリューションと、1年間の更新契約を締結していました。
しかし、インフラを提供するNECとの契約更新がNECキャピタルソリューションの手続き漏れにより行われず、11月1日をもって契約が切れてしまう事態となり、クラウド上に保存されていたデータが削除されました。
クラウドサービスを使ったインフラは、一般的に契約終了を終了するとセキュリティの観点からデータが復旧できないように削除されます。
当初は「ふくいナビ」のウェブサイトの復旧には少なくとも3カ月以上かかるといわれ、さらに、これまで蓄積したデータは復旧不可能と思われていました。その後、運用保守を担当する事業者も交えて調査したところ、バックアップが存在することが判明し、復旧の目処がついたことが報告されました。
本障害は、更新漏れという人為的ミスにより発生した、非常にお粗末なシステム障害ですが、自社で対策のしようのない原因でデータが全部消失する可能性があるという、予期していないトラブルのニュースで世間を驚かせました。
システム障害の大半は人的ミス

東証や「ふくいナビ」の事例のように、システム障害の大半は「人的ミス」が原因であることが多く、さらに比較的単純なミスによって障害が発生しています。
逆に、システムの動作(プログラム)そのものは、事前にしっかりと検証されているケースが多く、それが原因で障害が発生するケースはまれです。
システム障害を未然に防ぐ方法はあるのか?
システム障害に備えて、どれだけ対策をしたとしても、システムが人の手で作られる以上、トラブルの発生をゼロにすることはできません。
発生しないよう努力する必要はありますが、発生した場合はミスを受け入れつつ次善の対応に努めることが大事です。
データバックアップという保険
「ふくいナビ」の事例では、運よく約1ヶ月前のバックアップが見つかり、復旧の目処が立ちましたが、障害が発生した時の保険として、日々データをバックアップすることをお勧めします。
またクラウド上のサービスであれば、契約が切れた時に備え、ローカルPCなどに外部バックアップを取ることもお勧めです。
データバックアップを取ることはよいことなのですが、まれに個々の判断で守秘義務等に抵触しない範囲で自主的なバックアップを取る担当者もいます。
障害発生時に、バックアップが担当者ごとにバラバラに存在していると、どのバックアップを使用すべきか判断できなくなるため、基本的にはチームや会社の単位で計画を立ててバックアップを取ることや、データ保全のプロに依頼することをお勧めします。
トラブルを発生させると…
責任の所在にもよりますが、開発側の原因により障害を発生させると、対応に多大な時間を割かれるばかりか、今後の取引にも大きな影響を残します。
具体的には…
・別案件の契約も単価を削られる
・契約外の業務を押し付けられる
など、障害を起こした責任から、断りにくい心理状態につけこまれ無理難題を強要されるケースもあります。
あまり普段から気にしている方はいないと思いますが、トラブル発生に備えて事前に契約形態と責任の範囲を把握しておきましょう。責任範囲外なのに自分の責任のように受け止めて対応を行ってしまうと、後々良くない状況に陥る可能性があるので注意が必要です。
システムトラブル時のエンジニアに対する影響
システムトラブルが発生した場合、エンジニアは契約形態(請負開発・SES・派遣契約など)によって責任の所在が変わります。
まずは、それぞれの契約形態の特徴を確認しましょう。
| 請負契約 | 準委任契約 (SES) | 労働者 派遣契約 | |
| 完成責任 | あり | なし | なし |
| 瑕疵担保責任 | あり | なし | なし |
| 指揮命令権 | 受注側 | 受注側 | 受注側 |
ポイントは瑕疵担保責任で、請負契約では瑕疵担保責任があるため、瑕疵担保期間中であればシステムトラブルの責任を負う必要があります。
準委任契約(SES)、労働者派遣契約の場合、瑕疵担保責任がないため、たとえ障害が発生した際でも、エンジニアに対する責任は発生しません。
フリーランスの場合は、個々の契約内容によって責任の所在が変わるため一概には言えないのですが、瑕疵担保責任があるような契約を結んだ場合は、トラブル発生時の責任を負う可能性があります。契約の際はその内容についてしっかりと確認しておくよう心掛けておきましょう。
トラブルは事後処理が最重要
システムが人の手で作られている以上、システムトラブルをゼロにすることはできません。もしトラブルが発生した場合、原因追及をおろそかにしないことが大事です。
起きてしまった障害はしかたありません。
エンジニアとして出来る原因追求や、復旧に向けた対策、再発防止策を素早く打つことで、企業イメージのダウン、顧客との関係悪化を少しでも回避するようにしましょう。